Machine learning
As life becomes more automated, we are integrating these technologies into our daily routines. With the rise of surveillance infrastructure, there's an increasing reliance on these advancements to make our lives more convenient.
In this webpage, I embark on a project to identify specific cat breeds. This tool, which can be found on Teachable Machine, allows me to classify five cat breeds: American Shorthair, Bengal, British Shorthair, Devon, and Maine Coon. After uploading the relevant information to the website and setting up the classifications, I proceed to test the system's accuracy in recognizing these breeds.
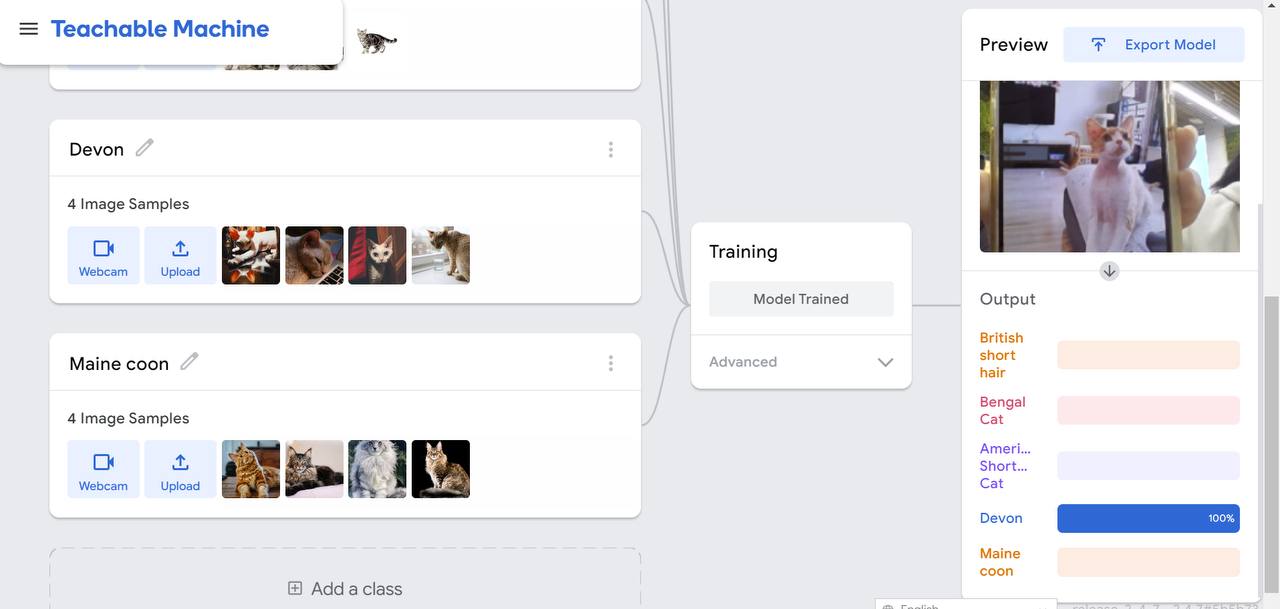
For each breed, we trained the system using four pictures per category. After training, we tested the model by inputting a new picture and observed the outcome, confirming that the system correctly identified the breeds.
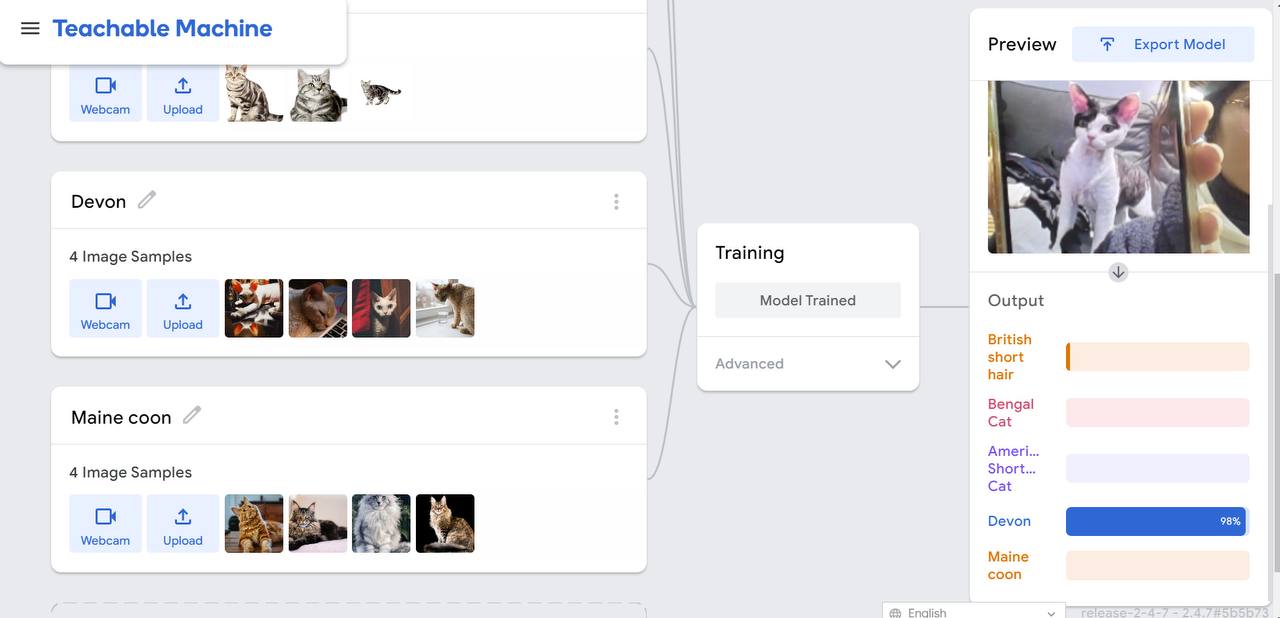
Although the results generally appear precise, there are instances of inaccuracies. For example, when I inadvertently photobomb the frame, the system sometimes mistakenly identifies me as a specific breed of cat.The misidentification is likely due to the limitations of the machine learning model used in the Teachable Machine project. Here are some key factors contributing to this outcome: