Web scraping
Web scraping, also known as web harvesting or web data extraction, involves using automated tools to fetch and extract data from websites.This process is typically performed by software that simulates human web browsing to collect specific information from web pages.
On this page, I will demonstrate my process of web scraping on YouTube using the WebScraper.io extension. The focus of my project is to scrape videos related to 'Travel Europe' on YouTube. My aim is to identify popular destinations and understand the types of travel videos that resonate with viewers. To begin, I entered 'Travel Europe' as my search query on YouTube. Next, I created a new sitemap and added new selectors to extract key components from each video, including the title, release date, link, and view counts.
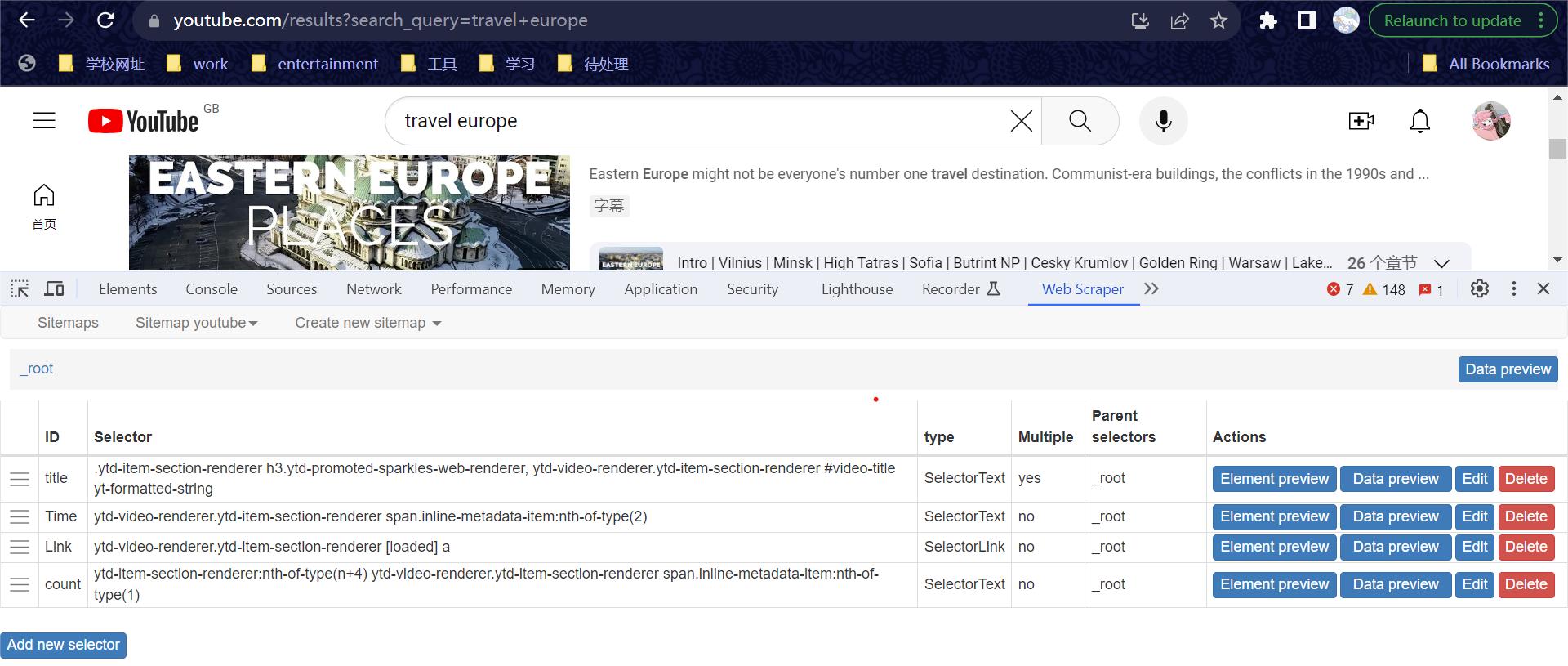
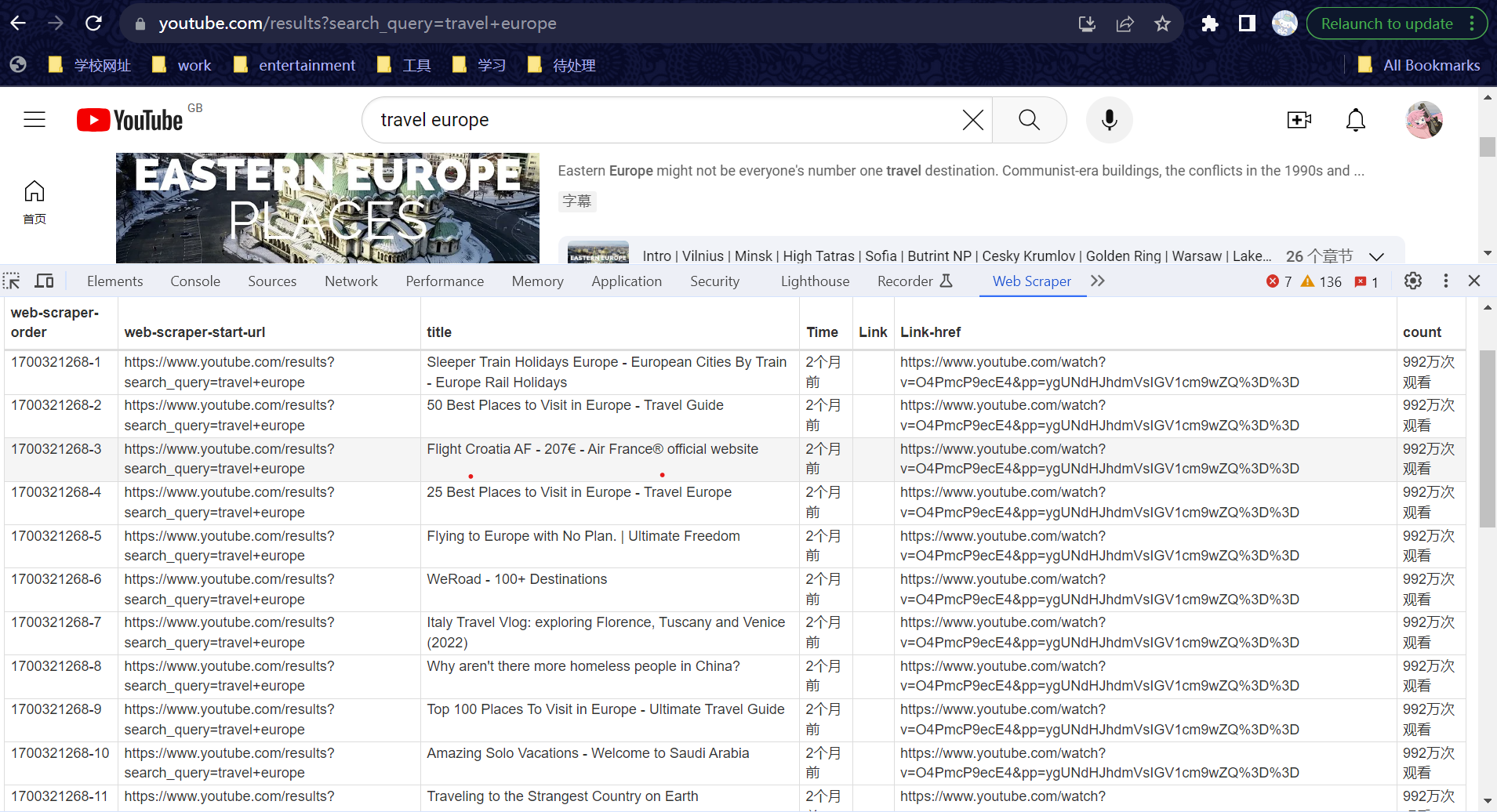
Below is a portion of the output chart I generated. It visibly illustrates the data I aimed to capture. However, there's an issue with the time and view counts, which are not displaying correctly. They appear to be incorrectly scraped, remaining constant at a single number instead of varying as expected. I'm currently unsure of the cause of this discrepancy.
Web scraping is a potent tool for organizing large datasets, enabling detailed research and analysis. It has become a prevalent method for commercial applications. Companies frequently use web scraping to analyze consumer behaviors, customizing content to match viewer preferences.
For instance, when analyzing YouTube to determine which travel videos are most popular, companies can similarly scrape data to identify influential content creators for potential advertising collaborations.
However, the reliability of web scraping can be compromised due to its reliance on software systems, which may encounter technological issues. Additionally, there's a risk of inaccuracies if the data source is flawed or contains erroneous figures, potentially impacting the quality and accuracy of the analysis.